使用Ollama本地运行大语言模型

Ollama是一个用于部署和运行大语言模型的轻量级开源框架,在Windows、Linux、macOS三种主流操作系统均可安装使用,使用Ollama我们可以轻松在本地运行大语言模型,或是将大语言模型的能力集成到聊天客户端、智能体平台等场景。Ollama强调隐私、安全性和易用性,我们部署的大语言模型可以是完全本地运行的,不依赖云服务和互联网连接。Ollama内部封装了llama.cpp推理引擎,同时官方维护了一个模型仓库,Ollama命令行工具提供了十分方便的模型管理命令,我们可以像下载和运行Docker镜像一样部署大语言模型,使用非常方便。这篇文章我们简单介绍Ollama工具的安装和使用,以及如何与其它平台集成。
官方网站:https://ollama.com/
Github地址:https://github.com/ollama/ollama
PC配置需求
使用Ollama本地部署模型对PC配置有一定要求,迄今为止Nvidia GPU和CUDA仍是最成熟的选择,理论上从较老的GTX750Ti到最新的RTX50系列都可以运行Ollama,AMD GPU的ROCm覆盖的型号则相对少一些,具体可以参考官方文档。如果实在没有GPU,Ollama也可以纯CPU运行,只不过速度恐怕不尽如人意。
对于本地部署的大语言模型,8b(即80亿参数)规模是比较合适的入门级尺寸,在Q4量化下我们至少需要8GB显存(VRAM)来运行它,Nvidia RTX20、30、40、50系列的60级别以上显卡都可以完美运行,至于内存通常满足当前主流的32GB就足够了。实际上,如果出现显存不足的情况,Windows操作系统也能自动利用内存补足(在任务管理器中我们可以看到共享显存相关的信息),但使用共享显存会拖慢运行速度。GTX9、10或更古老的显卡通常显存较小,但仍有Tesla M40、P40、P100这类计算卡可以选择,虽然运行速度较慢,未来也可能失去新版本CUDA的支持,不过目前仍可以使用。至于8b以下的模型通常难以处理通用日常任务,它们是为专用场景微调而准备的。
当前效果不错且适合本地运行的模型选择参考:
| 显存 | 模型 | 量化 | 说明 |
|---|---|---|---|
| 8GB | qwen3:8b | Q4_K_M | Qwen3系列是阿里开源的大语言模型,在8b规模里目前是效果最好的一档,适合文本处理和简单的Agent场景 |
| 12GB | gemma3:12b-it-qat | QAT(Q4) | Gemma3系列是谷歌开源的多模态模型,支持输入图片,适合文本处理和多模态交互 |
| 16GB | gpt-oss:20b | MXFP4 | GPT-OSS系列是OpenAI开源的MoE架构模型,效果很好而且速度在RTX50下非常快,16GB显存建议使用 |
| 16GB | qwen3:30b-a3b | Q4_K_M | Qwen3系列的MoE架构模型,可以满足较为复杂的文本处理、任务规划、工具调用等工作,16GB显存其实非常勉强,会溢出一点到内存导致速度较慢(差不多15token/s),如果有24GB显存是最好的 |
Ollama安装
我们直接在官方主页中找到Download按钮下载即可,对于Linux系统它需要我们执行一个安装Shell脚本,对于Windows系统则有一个exe格式的安装包。
安装完成后,我们打开Linux或Windows命令行即可使用Ollama了。它的使用很简单,我们可以执行以下命令查看帮助信息。
ollama help
下载和运行大语言模型
前面我们提到过,Ollama底层的推理引擎是llama.cpp,它支持的是GGUF格式的模型。不过Ollama自己维护了一个模型仓库,大部分支持GGUF格式的主流模型都可以在这个仓库中找到,我们可以直接在其中搜索我们需要的大语言模型并通过Ollama命令下载和运行。Ollama仓库中这些模型的维护和Docker镜像有些类似,模型有名字和Tag两个属性作为坐标,例如llama3:8b、qwen3:8b等,我们可以在页面上选择不同Tag查看这些模型的参数规模、量化等信息。
不过在此之前,我们可以先修改一下Ollama的模型缓存地址,LLM的文件尺寸都非常大,例如8b左右规模的模型通常在4~5GB,30b规模的模型更是要占用十几GB的存储空间,Ollama默认会将这些缓存文件放置在用户目录(对于Windows通常是C盘),我们可以使用环境变量OLLAMA_MODELS将其指定到其它目录,避免耗尽系统硬盘导致麻烦。
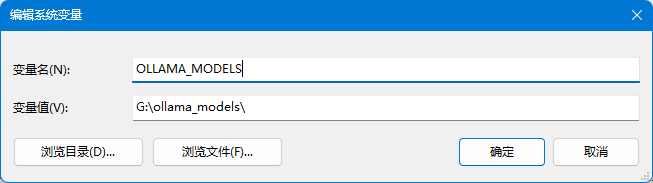
环境变量设置完成后,需要重启Ollama使其生效。
注:Windows下新版本的Ollama自带了一个GUI界面,其中也可以调整模型的存储路径,这两种方式配置都可以生效。
具体下载和运行模型需要使用Ollama命令行,下面例子中我们下载并运行qwen3:8b模型,它默认是8b规模和Q4量化的,需要8GB的显存即可运行。
ollama run qwen3:8b
运行后如果模型尚未下载,我们需要等待下载完成,如果一切正常,我们就会进入一个交互式的命令行聊天界面中。

这个界面中我们可以输入/?查看命令提示,如果想要退出这个界面,可以输入/bye。
如果只想下载模型不想运行,可以使用pull命令。
ollama pull qwen3:8b
如果想要查看我们已经安装了哪些模型,可以执行以下命令。
ollama list
如果不想要某个模型了,可以使用rm命令移除。
ollama rm qwen3:8b
Ollama集成
使用Cherry Studio(推荐)
Ollama提供了命令行和HTTP API方式访问部署的模型,但对于普通用户来说可能直接使用不是很方便,不过目前有很多强大的客户端工具可供我们选用。Cherry Studio是目前人气较高的一款开源大语言模型客户端。
官方主页:https://www.cherry-ai.com/
Cherry Studio是Electron开发的桌面软件,我们可以直接在官网找到安装包,然后下载安装即可。
在设置 - 模型服务界面中,我们可以添加Ollama相关的信息,对于本地部署的模型,API密钥默认留空即可,API地址填写http://localhost:11434,然后点击管理按钮,Cherry Studio会调用Ollama的模型列表接口列出我们已下载的模型,点击后面的加号按钮即可将其添加到Cherry Studio可选模型列表中。调用时的参数如温度、Top-P、上下文等可以在助手的设置界面中配置。
使用Open WebUI
Open WebUI(原Ollama WebUI)是另一个使用广泛的开源项目,它本身是一个Web程序,提供了类似ChatGPT的Web版AI聊天图形界面,并默认支持连接到Ollama后端。Open WebUI可以使用Docker部署,如果你不喜欢Electron桌面软件或者希望在NAS、VPS上部署,Open WebUI是个不错的选择。不过个人说实话不是很推荐Open WebUI,这里不得不吐槽下它的图形界面(尤其是设置部分)做的实在太糟糕了(可能是由于作者精力有限),真的很难想象这是个始于2023年的项目,如今随便让Claude或Gemini写页面都不至于如此不堪,不过话又说回来,也不是不能用,希望未来版本能有改进。
Open WebUI提供了Docker镜像供我们部署,对于Windows操作系统我们需要安装Docker Desktop(基于WSL2)。安装好Docker后,我们直接执行以下命令下载并运行Open WebUI的镜像。
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
注:如果不想Open WebUI在Docker启动后自动启动,可以将--restart设置为no。
启动完成后,我们使用浏览器访问http://localhost:3000即可进入Open WebUI,由于程序设计上是支持多用户的,第一次使用可能需要设定账号和密码。进入主界面后,在界面的左上角我们可以选择Ollama中已经安装的模型。

集成到Dify
Dify是一个低代码的开源AI应用开发和流程编排平台,类似Open WebUI,它也可以作为私有部署的Ollama客户端使用,而且功能要更加强大。不过Dify的架构比Open WebUI复杂得多,部署可能会遇到很多坑,官方提供了Docker Compose配置文件,我们可以直接基于这些配置文件尝试启动所需的所有Docker容器。
首先拉取Dify的源代码仓库。
git clone --branch 1.11.4 https://github.com/langgenius/dify.git
注:1.11.4是当前版本的Tag名,你在部署时可能已经有更新的版本了。
然后执行以下命令启动项目,由于要下载若干个较大的Docker镜像,因此速度可能很慢,需要耐心等待。
cd dify/docker && cp .env.example .env && docker compose -p dify up -d
注:如果不想Dify在Docker启动后自动启动,可以将docker-compose.yaml中对应容器的restart: always设置为no。
在Dify的设置界面里,我们需要安装Ollama集成的插件,然后配置模型信息。其中需要注意Ollama的接口地址,由于我们是在Docker容器中,因此应该填写http://host.docker.internal:11434。
直接调用Ollama的HTTP接口
实际上,Cherry Studio、Open WebUI和Dify等之所以能够连接Ollama,是因为Ollama在本地的11434端口启动了一个HTTP服务,我们也可以直接用程序或Postman调用这个接口。
POST http://localhost:11434/api/generate
除了基础的文本生成,Ollama还提供了多轮对话聊天、生成Embedding、列出可用模型、下载模型、删除模型等功能的HTTP接口,具体参考官方文档即可。
此外,除了Ollama原生的HTTP接口,Ollama目前还支持OpenAI标准的兼容接口和Anthropic标准的兼容接口,这非常重要,许多软件或框架可能没有单独对接Ollama的接口规范,而是仅支持OpenAI或Anthropic标准接口,Ollama提供的这些接口兼容模式可以让我们直接把Ollama“假装”成OpenAI或Anthropic的接口接入。
定制Modelfile
Modelfile是Ollama的核心特性,它类似Docker镜像的构建脚本,Modelfile是一个模型的基础描述文件,我们在Modelfile中可以指定基础模型、参数、输入文本模板、系统提示词等,来基于一个基础模型定制大语言模型的使用。
创建Modelfile
Modelfile可以在任意目录创建,文件名可以是任意的(一般文件名直接就叫Modelfile),下面是一个例子。
FROM qwen3:8b
PARAMETER temperature 1
SYSTEM """
You are an AI assistant named Aiko living in cyberspace. You help people with your knowledge. You always add emojis in what you say. You always answer all questions to the best of your ability. You reply in English.
"""
Modelfile中,From指定了基础的模型,PARAMETER我们这里设置了模型的temperature参数,此外我们还设置了专门的系统提示词。创建好Modelfile后,我们执行以下命令将定制的模型导入到Ollama中,Ollama会自动复用基础模型的相关权重文件,因此不必担心Ollama会重复下载。其中,demo:latest是我们自定义的模型和标签名。
ollama create demo:latest -f Modelfile
创建完成后,我们就可以运行测试效果了。
ollama run demo:latest
我们在Modelfile中指定了temperature、系统提示词等参数,其实这些参数在HTTP接口内也支持传递,接口中的参数优先级更高,只有当调用接口没传相关参数时,才会使用Modelfile中指定的默认值。
查看已有模型的Modelfile
对于已有的模型,我们可以使用以下命令查看其等效的Modelfile。
ollama show qwen3:8b --modelfile
直接加载GGUF模型文件
除了Ollama仓库提供的模型,我们也可以直接加载下载到本地的GGUF模型文件,和前面类似,这也需要创建一个Modelfile,下面是一个最简单的例子。
FROM ./xxx.gguf
代码中,FROM后面的内容是GGUF模型文件的路径。和之前一样,我们还可以在这里指定默认的配置参数、系统提示词等。另外一个注意点是GGUF内是否自带正确的输入文本模板,一般来说新的GGUF权重文件都是自带的,但如果没有自带或者自带的存在错误,我们可能还需要手动添加或覆盖TEMPLATE配置,否则模型可能表现的不正常。创建好模型描述文件后,我们使用Ollama命令行工具即可将模型注册到本地。
ollama create <模型名> -f <Modelfile文件>
此时我们就可以使用ollama list和ollama run等命令操作这个模型了。