Cloudflare白嫖指南

Cloudflare创立于2009年,是全球最知名的CDN服务提供商,近几年的发展更是尤其迅速,Cloudflare提供了网站加速和保护服务,在国际上使用非常广泛,据说它承载了整个互联网20%的流量。Cloudflare的很多服务提供了不同的付费类型,包括免费、额度内免费和付费计划,免费计划也可以使用许多实用有趣的功能,堪称业界良心。
官方网站:https://www.cloudflare.com/
公共DNS
参考文档:https://developers.cloudflare.com/1.1.1.1/
1.1.1.1是Cloudflare运营的公共DNS,除此之外,Cloudflare还提供了DoH服务,至于什么是DoH可以参考知识库中有关网络协议和DNS的相关章节。
在Firefox浏览器中已经内置了使用Cloudflare的DoH解析域名的选项,我们可以在Privacy & Security中找到相关的配置。
DNS解析服务
参考文档:https://developers.cloudflare.com/dns/
Cloudflare提供了DNS解析服务,我们可以直接在Cloudflare申请域名,也可以在其它地方申请域名,然后将域名的DNS服务器改到如下地址。
NS fay.ns.cloudflare.com
NS paul.ns.cloudflare.com

配置后,我们就可以在Cloudflare的控制台页面里添加站点,维护相关的DNS配置了。
实现DDNS
Cloudflare的DNS解析服务提供了可以免费使用的REST API,我们调用这些API也可以操作域名的解析记录,因此可以基于这个功能实现免费的DDNS。想要调用这些API,首先我们需要区域ID和API令牌这两个东西,它们可以在Cloudflare站点控制台的右下角找到。
此时我们就可以编写一个脚本来调用API自动更新DNS记录了。我这里实现过一个自动更新IP解析记录的工具,之前放在了一个树莓派上,用来实现树莓派的公网IPV6访问。
https://github.com/gacfox/cloudflare-ddns
简而言之,这个工具会检查当前主机获得的公网IP地址,并和Cloudflare上面配置的A或AAAA解析记录比较,在IP有变化时更新,这样我们就实现了一个免费好用的DDNS功能。
CDN反向代理

Cloudflare提供了免费的CDN代理,并基于此提供了一些免费的网站防护功能,这也是大部分人选择Cloudflare的原因,在DNS配置界面,我们可以看到这朵黄色的云,Proxied状态即为开启代理,DNS only为代理关闭状态。
使用CDN代理有很多好处,比如:
加速访问:用户直接访问我们网站的主机可能由于地区等原因网络链路太长,速度很慢,而Cloudflare有自己优质的全球线路,用户可以通过CDN的代理节点访问我们的网站。而Cloudflare的代理节点广泛使用了Anycast技术,因此能够保证用户的访问速度。
安全: 攻击一个网站时,我们可能会用nmap之类的工具扫一下网站主机的开放端口,没准主机上运行的哪个服务就有漏洞,还被粗心的服务器管理员开到了公网上。使用CDN代理则能够隐藏源站,网站的真实IP是被Cloudflare反向代理的,攻击者无法得知也无法扫描。
Cloudflare Worker
参考文档:https://developers.cloudflare.com/workers/
Cloudflare Worker是一种Serverless服务,我们可以使用JavaScript编写一些代码并免费部署到Cloudflare Worker平台,用于提供HTTP接口服务。Cloudflare Worker是免费使用的,不过有一些调用次数的限制(每日100000次)和CPU执行时间的限制,但对于个人用户来说已经完全够用了。Worker还能搭配KV、D1数据库使用,或是R2对象存储(付费,但有免费额度),我们可以用Worker实现很多有意思的功能,比如博客的服务端、评论系统、图床等。
Worker开发
我们可以直接在Cloudflare的控制台上创建Worker并在线编辑,但我个人不喜欢这种方式,这里比较推荐在本地创建工程,完成代码的开发和调试后使用wrangler部署。wrangler是一个基于NodeJS的命令行工具,也是我们开发Worker工程调试发布时需要用到的工具。默认创建的工程中,wrangler被封装在NPM Scripts里,我们有时也可能需要手动调用它。
要创建一个Worker工程,我们可以执行以下命令。
npm create cloudflare@latest
该命令是交互式的,需要我们输入工程的一些基本信息,比如项目名、工程模板等,我们可以选择Hello World工程模板。工程创建完成后,会生成如下的工程目录结构(省略无关文件):
src
|_index.js # 工程代码
wrangler.json # Worker的描述文件
package.json # NodeJS工程的描述文件
index.js这个代码文件也是我们服务的入口文件,它的位置其实是在wrangler.json中指定的,默认创建的代码内容如下。
src/index.js
export default {
async fetch(request, env, ctx) {
return new Response('Hello World!');
},
};
代码非常简单,它会在所有请求下返回Hello World!信息。在本地开发时,我们可以执行npm run dev,wrangler会为我们模拟Cloudflare的环境来执行Worker程序。需要部署时,可以执行npm run deploy部署这个Worker到我们的Cloudflare账号,第一次执行时可能需要登陆,我们根据提示操作即可,执行成功后我们就可以在Cloudflare控制台页面上找到部署好的Worker了。此时我们可以用浏览器访问Worker默认的域名进行测试。
有关Worker开发相信大家一看这个fetch(request, env, ctx)就懂了,和大多数服务端框架设计的都差不多,我们直接参考文档上手开用即可,Cloudflare Worker反而还没那么多花里胡哨的特性,设计的那就是一个简单(简陋)。
此外,我们还可以为Worker绑定我们自己的域名。我们在站点的DNS记录中创建一个子域名的DNS记录,IP地址随便填写,然后在Worker Routes中创建路由规则即可。
AI
参考文档:https://developers.cloudflare.com/workers-ai/
Cloudflare最近新发布了AI能力,提供了语音、图像和自然语言处理相关的许多开源AI模型的API,我们可以在Worker中免费调用这些AI模型资源,实现例如图像识别、AI聊天等功能。这部分Cloudflare目前提供了免费计划,简单玩一下是完全够用的。
在Worker工程的wrangler.toml中,我们需要配置binding字段注入相关的功能。
[ai]
binding = "AI"
配置完成后我们就可以使用env.AI调用当前帐号下的AI模型了,注意这里的AI能力都是Cloudflare云端提供的,测试环境中调试时也会使用账号中的免费额度。
下面例子代码调用了Llama3-8b-instruct大语言模型,实现了一个让AI回答问题的功能。
export default {
async fetch(request, env) {
if (request.method === 'OPTIONS') {
return new Response(null, {
headers: {
'Access-Control-Allow-Origin': '*',
'Access-Control-Max-Age': '86400',
'Access-Control-Allow-Methods': 'GET, POST',
'Access-Control-Allow-Headers': 'Content-Type',
},
});
} else {
const url = new URL(request.url);
const path = url.pathname;
if (path === '/api/v1/chat') {
return await handleChat(request, env);
} else {
return new Response('Request URL not found', { status: 404 });
}
}
},
};
const handleChat = async (request, env) => {
// 表单校验
if (request.method !== 'POST') {
return new Response('Method not allowed', { status: 405 });
}
const reqJson = await request.json();
if (reqJson?.content) {
// 调用大模型
const prompt = 'You are a helpful AI assistant.';
const messages = [
{ role: 'system', content: prompt },
{ role: 'user', content: reqJson.content },
];
const stream = await env.AI.run('@cf/meta/llama-3-8b-instruct', {
messages,
stream: true,
});
return new Response(stream, {
headers: {
'Access-Control-Allow-Origin': '*',
'Access-Control-Max-Age': '86400',
'Access-Control-Allow-Methods': 'GET, POST',
'Access-Control-Allow-Headers': 'Content-Type',
'content-type': 'text/event-stream; charset=utf-8',
},
});
} else {
return new Response('Request param invalid', { status: 400 });
}
};
代码非常简单,我们收到请求后拼装了系统提示词和用户输入的提示词发送给Llama3大模型,最后以流的形式读取其输出,以SSE的形式返回给用户,这也是许多AI聊天前端页面的常见实现方式,不过我们这个例子比较简陋,没有实现对话历史等复杂功能,这里代码仅供参考。
KV
参考文档:https://developers.cloudflare.com/kv/
Cloudflare提供了免费的KV数据库供Worker使用,免费计划有调用次数等限制,不过也完全够用了。我们可以直接在Cloudflare的控制台上创建KV命名空间,然后在Worker中就可以直接调用,我这里创建了一个叫MY_KV的命名空间用来测试,创建后会生成一个ID用来关联KV数据库的访问。
在Worker工程的wrangler.toml中,我们需要配置binding和id字段,关联该Worker操作的KV数据库。
[[kv_namespaces]]
binding = "MY_KV"
id = "30c11a8b069142e18ba39521d4a51d63"
配置中binding字段是可以随意起名的(但要符合JavaScript的变量命名规范),它可以不是KV库名或命名空间名,只是一个用来在代码中访问KV库的变量名,库的关联是通过id字段实现的。
配置完成后,我们就可以使用Worker访问KV数据库了。
export default {
async fetch(request, env, ctx) {
// 写入数据
await env.MY_KV.put('key', 'hello');
// 读取数据
let value = await env.MY_KV.get('key');
return new Response(value);
},
};
D1
参考文档:https://developers.cloudflare.com/d1/
D1是一个Serverless的关系型数据库服务,目前处于beta阶段,但目前官方表示后续也将持续提供免费计划。免费计划有一些调用次数上的限制,具体可以参考相关文档。D1数据库可以在Cloudflare控制台页面上直接创建,我这里创建了一个测试用的mydb数据库。
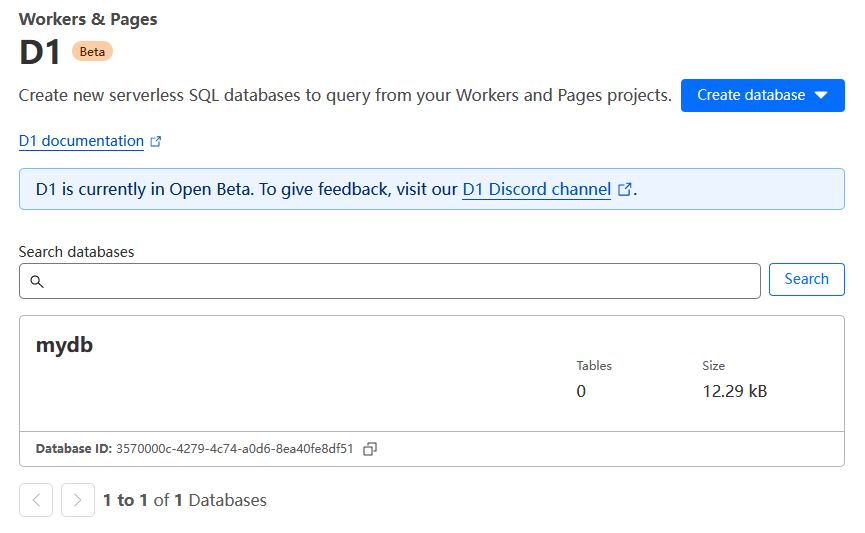
创建数据库后,我们还需要在Cloudflare控制台上创建表。我这里创建了一个t_user表。

类似KV,在Worker工程的wrangler.toml中,我们也需要配置相关字段关联数据库。
[[d1_databases]]
binding = "DB"
database_name = "mydb"
database_id = "3570000c-4279-4c74-a0d6-8ea40fe8df51"
配置完成后,我们就可以在Worker中用env.DB访问D1库了。下面代码中我们执行了一个查询请求,查询t_user表中的数据并以JSON格式输出。
export default {
async fetch(request, env, ctx) {
const sql = 'select * from t_user';
const { results } = await env.DB.prepare(sql).all();
return Response.json(results);
},
};
Cloudflare Pages
参考文档:https://developers.cloudflare.com/pages/
Cloudflare Pages类似Github Pages或Vercel,是一个用来部署静态站点的服务,目前也可以免费使用,此外它还有Pages Functions也能够实现一些服务端功能。Cloudflare Pages支持很多前端框架的自动构建,比如常用的Hexo、NextJS、Vite等,也可以部署我们的自定义站点。我们这里以Hexo为例进行介绍。
执行以下命令,创建Hexo工程。
npx hexo init pages-demo
此时hexo命令行工具会自动创建一个示例工程,我们需要先将它上传到Github上,然后即可创建Pages,创建时我们需要根据提示连接Github并授权。在构建设置中,编写构建命令和构建输出内容的文件夹名,然后点击Save and Deploy即可。
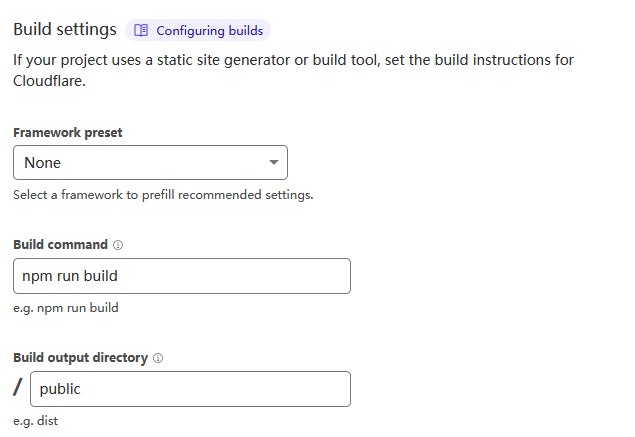
等待一会构建完成,即可访问我们的站点了。
如果需要为Pages绑定域名,可以在Cloudflare中新建DNS记录,并使用CNAME类型记录解析到Pages默认的域名上。
此外,除了使用Github,我们也可以直接从本地上传站点的资源文件到Cloudflare上,但个人不建议这么操作,如果我们的站点文件比较多,上传大量小文件容易卡死,还是从Github持续集成更稳定和好用。
总结
Cloudflare提供了很多好玩的免费服务,我们可以用它的DNS服务器管理我们的域名解析,使用它提供的CDN加速网站访问,还能用Worker和Pages两种Serverless服务编写我们自己的站点,以及免费使用KV和D1数据库实现数据持久化,但还请不要滥用Cloudflare的免费服务,以使这些福利能存活的更久一些。