浏览器反调试的几种姿势
浏览器反调试是Web开发中的一种常见安全措施,它能起到保护前端源码、反爬虫、反服务端接口调试的目的,这里我们介绍一些常见的浏览器反调试手段。
基本原则
“安全”永远不是“加密”两个字就能概括的,在具体学习浏览器反调试手段之前,我们一定要理解两个基本概念。
前端无加密:下面介绍的各种骚操作目的并不是实现密码学上的“安全性”,而是“反调试”。我们要记住一个原则:对于使用系统的用户来说,前端无加密,毕竟正在运行着的源码都在用户的浏览器里,用户可以自由的查看代码逻辑、修改源码,这怎么可能做到“加密”呢?用户可以看到的内容就一定可以爬取,用户通过页面上操作调用的接口就一定可以手动调试!而“反调试”的本质是一种“劝退”手段,是给程序逆向增加门槛,给破解源码逻辑、破解接口协议增加成本的手段,它让试图调试源码寻找系统漏洞的人不得不付出大量精力才能摸清代码的运行逻辑,甚至付出的精力要远大于重新实现一模一样的功能,进而内心受挫、怀疑人生,甚至血压升高、怒砸电脑,不得不放弃调试。
安全有成本:虽然理论上一个系统可以做到既“安全”又“好用”,但无数经验告诉我们,安全必然是有成本的。系统变得更安全,可能也意味着程序逻辑变得更复杂,程序员开发调试变得更困难,系统性能下降变得卡顿,功能上的诡异bug频出,用户体验变差等。总而言之,系统在安全方面考虑的越周到就越难用。
注:至于加密通信防止中间人窃听,这是由TLS实现的,只要使用HTTPS协议通信,它已经基于数字签名、密钥交换、对称加密等技术实现了密码学上的计算安全性,不可能被窃听或篡改,我们没必要画蛇添足再在应用层之上实现一遍。如果使用HTTP通信,那就不可能保证安全,即使你在HTTP之上又实现了一遍TLS的逻辑也不行,因为JavaScript本身就可能被中间人篡改。
代码反调试
禁用F12
禁用F12是最初级的反调试手段,包括屏蔽浏览器中的F12、右键等试图打开浏览器调试器(DevTools)的操作,或许连最业余的那部分攻击者也拦不住,下面是一些例子代码。
window.onload = function () {
// 屏蔽F12
document.onkeydown = function (e) {
if (e.key === "F12") {
return false;
}
};
// 屏蔽右键contextmenu
document.oncontextmenu = function (e) {
return false;
};
};
代码中我们重写了键盘按下F12和右键点击对应的事件,让它们直接返回false,此时用户试图打开浏览器的调试器就不会有任何反应了。
绕过方式:在加载页面前先打开调试器就行了。
无限debugger
无限debugger是一种比较基础也比较温和的反调试手段,通常要和其它反调试手段配合使用,恰当运用能够拦住水平一般的渗透测试人员。
浏览器中我们可以使用debugger指令,它和在调试器里打断点有相同的效果,我们用setInterval()写一个死循环不停的执行debugger指令,用户只要打开调试器就会卡在断点上,代码不会自动继续执行,以此阻碍逆向调试,比较简单的无限debugger代码如下。
window.onload = function () {
setInterval(function () {
debugger;
}, 10);
};
绕过方式:如果你只是在工程中简单的插入上述代码,那还是太菜了,绕过方式有很多种,比如在Chrome的调试器中对应代码行点击右键选择Never pause here,可以直接禁用一个位置的断点,实际开发中无限debugger通常需要一些更隐晦的写法,将在后文介绍。
判断调试器是否打开
虽然浏览器的API并没有提供一种直接判断F12调试器是否打开的函数,但还是有一些方法能否判断,当然,这里使用的都是非常规的手段,不同浏览器的不同版本可能具体的表现也不同,这里不保证这些方法的兼容性,贸然使用可能带来意外后果。
下面例子通过覆盖一个正则对象的toString()配合console.log()方法循环判断浏览器的调试器是否打开,大部分浏览器在调试器未打开时console.log()不会实际执行,因此不会触发反调试逻辑,然而调试器一旦打开,反调试逻辑就会执行并无限申请内存,卡死用户的浏览器。
window.onload = () => {
var o = /.*/;
var arr = [];
o.toString = () => {
// 卡死你
arr.push(new ArrayBuffer(1024 * 1024 * 1024));
return "";
};
setInterval(() => {
console.log(o);
}, 1);
};
当然,直接卡死浏览器可能太不友好了,我们也可以检测到打开调试器时直接跳转走。
window.onload = () => {
var o = /.*/;
var arr = [];
var timer;
o.toString = () => {
// 再见
location.href = "https://baidu.com";
if (timer) {
clearInterval(timer);
}
};
timer = setInterval(() => {
console.log(o);
}, 100);
};
绕过方式:上面这种反调试手段没有太好的绕过方式,一般手段是拦截HTTP请求并将JavaScript中的反调试逻辑去掉。配合压缩混淆后,想要绕过会有一定难度。
前端代码鬼畜化
下面介绍的反调试手段涉及JavaScript源码的编写方式,不过这里注意我们只是介绍其原理,而不是真的要这样编写代码,通常它们实际会在构建阶段由混淆器实现。
使用eval
代码鬼畜化有很多奇技淫巧,其中一个惯用手段是eval()。下面例子的功能是用户点击按钮时,读取<input>中的值并传入encryptData()函数。然而,代码中我们用eval()隐晦的调用了函数encryptData()并传递了input变量作为参数。
window.onload = function () {
var buttonEle = document.querySelector("#button");
buttonEle.addEventListener("click", function () {
var inputEle = document.querySelector("#password");
var input = inputEle.value;
var a = "ZW5jcnlwdE";
var b = "RhdGEoaW5wdXQp";
var ret = eval(Base64.decode(a + b));
console.log(ret);
});
};
function encryptData(data) {
// ... 一些稀奇古怪的加密逻辑
}
代码中,a + b实际是一个Base64编码的字符串encryptData(input),通过eval()执行后间接调用了对应的函数。eval的意义在于规避对代码进行全局搜索来找到函数的调用位置,这样的代码如果混在大量的业务逻辑代码中并进行了压缩混淆,渗透测试人员想找到究竟哪里调用了encryptData()函数还是有点难度的。
另一个例子,还是之前的无限debugger,但是我们换了一种写法,代码如下。
window.onload = function () {
var tom = "deb";
var jerry = Base64.decode("dWdnZXI=");
setInterval(function () {
eval(tom + jerry);
}, 10);
};
代码中,我们还是执行了debugger指令,只不过是通过eval()执行的,我们并没有在JavaScript代码中明确写一个debugger字符串,这样太容易被用户用工具全局搜索出来然后替换或是禁用断点了,我们采用了字符串拼接和Base64编码的方式(用到了base64库),隐晦的表达了要执行debugger指令。
插入无用逻辑
插入无用逻辑通常配合代码混淆使用,会给逆向调试造成更多的困难。下面代码中,if (input === a || input === b) {}就是一个具有迷惑性的判断,攻击者看到这段代码时,可能就会怀疑这个判断究竟有没有用,然后真的去分析encryptDataSimple()函数,当它反应过来时已经浪费了很多时间,实际上input几乎不可能输入ZW5jcnlwdE或RhdGEoaW5wdXQp这两个奇怪的字符串,这个判断永远不会执行。
window.onload = function () {
var buttonEle = document.querySelector("#button");
buttonEle.addEventListener("click", function () {
var inputEle = document.querySelector("#password");
var input = inputEle.value;
var a = "ZW5jcnlwdE";
var b = "RhdGEoaW5wdXQp";
var ret;
if (input === a || input === b) {
ret = encryptDataSimple(input);
} else {
ret = eval(Base64.decode(a + b));
}
console.log(ret);
});
};
function encryptData(data) {
// ... 一些稀奇古怪的加密逻辑
}
function encryptDataSimple(data) {
// ... 完全不会执行的逻辑
}
以源码形式给出上面代码可能很容易被看出来是一个假的判断,但如果再加上代码混淆就更具迷惑性了。
代码压缩
代码压缩简而言之就是将源代码合并成一行,更复杂一点的可能展开某些函数,或是替换一些关键字。代码压缩原本的目的是减小代码体积提升JavaScript文件的加载速度,在反调试方面也有一定的效果。JavaScript代码不压缩直接部署的情况在这个年代是比较罕见了,它一般出现在那些古早的网站中,尤其是那些非前后端分离的项目中。对于这类古早的项目,可以采用YUICompressor等工具手动对JavaScript代码进行压缩。
在现代的JavaScript项目中,如果使用Webpack、Rollup等打包工具,一般都会默认对源码进行压缩合并,因此不存在这个问题。
使用obfuscator混淆器
代码混淆是一个相对高级的源码保护手段,obfuscator是一个知名的代码混淆器,它的功能很强大,前面介绍的禁用调试器、无限debugger、随机插入无用逻辑等功能都已包含,因此如果使用obfuscator就不用手动实现那些功能了,我们正常编写源码即可。
obfuscator在Webpack和Rollup等构建系统下都有对应的插件,我们直接使用就可以。这里我们以Webpack为例进行介绍,执行以下命令安装相关依赖。
npm install --save-dev webpack-obfuscator javascript-obfuscator
下面是一个Webpack配置例子,这里只是作为一个示例,实际使用时具体配置可能由于obfuscator的版本不同而有些变化,具体配置选项可以参考文档。
webpack.config.js
const path = require("path");
const obfuscator = require("webpack-obfuscator");
module.exports = {
entry: "./src/main.js",
output: {
filename: "bundle.js",
path: path.resolve(__dirname, "./dist"),
},
plugins: [
new obfuscator({
compact: true,
// 随机控制流扁平化,注意对性能有约1.5x影响
controlFlowFlattening: true,
// 控制流混淆触发概率
controlFlowFlatteningThreshold: 0.75,
// 随机无用代码块
deadCodeInjection: true,
// 随机无用代码块触发概率
deadCodeInjectionThreshold: 0.4,
// 插入无限debugger
debugProtection: true,
// 无限debugger的延时
debugProtectionInterval: 10,
// 禁用源码中的控制台信息打印
disableConsoleOutput: false,
// 标识符的混淆方式 可选hexadecimal(十六进制)、mangled(短标识符)
identifierNamesGenerator: "hexadecimal",
// 全局标识符添加特定前缀,用于一个页面加载多个JS文件时,避免这些文件中混淆后的全局标识符之间发生冲突
identifiersPrefix: "",
inputFileName: "",
// 全局变量和函数名混淆
renameGlobals: true,
// 随机发生器种子
seed: 0,
// 是否开启sourceMap功能(用于调试阶段,生产环境应禁用)
sourceMap: false,
sourceMapBaseUrl: "",
sourceMapFileName: "",
sourceMapMode: "separate",
// 将字符串字面量放在一个特殊的数组中
stringArray: true,
// 字符串字面量编码,可选base64、rc4、none(不编码),以数组方式指定多个
stringArrayEncoding: ["base64", "rc4"],
// 将字符串字面量放在一个特殊的数组中的触发概率
stringArrayThreshold: 0.75,
// 混淆的目标环境,可选browser、node
target: "browser",
// 是否启用混淆Object对象键
transformObjectKeys: true,
// 允许启用/禁用字符串转换为unicode转义序列
unicodeEscapeSequence: true,
}),
],
};
经过混淆的代码将是如下的画风。
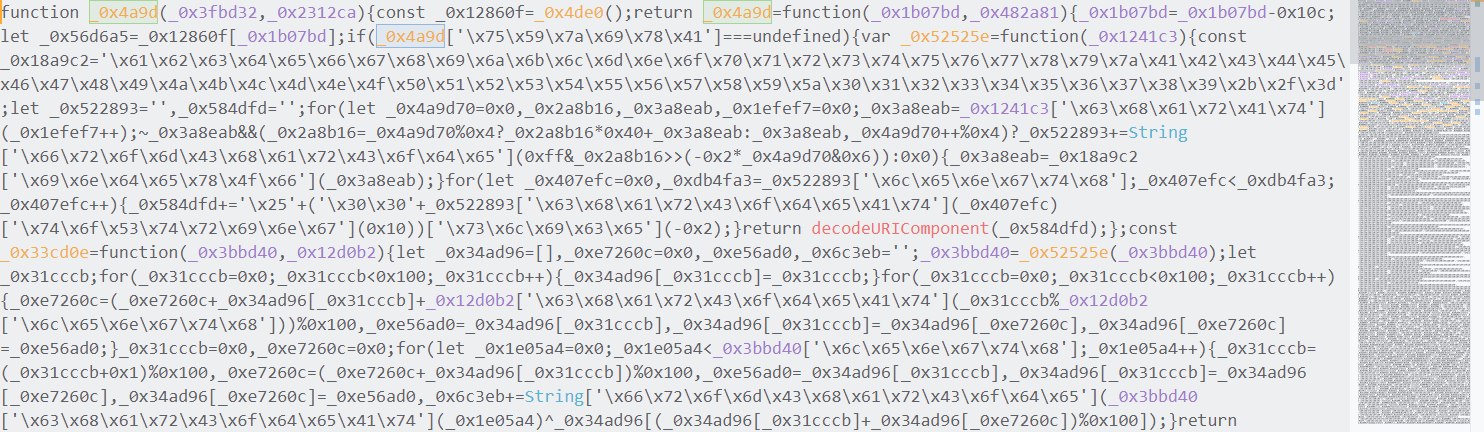
当然我们还是要记住,代码混淆或许可以拦住99%的攻击者,但仍并非绝对安全。
内容防复制
这里我们再额外介绍一些内容防复制的技巧。实际上,内容防复制是个伪需求,前面已经说过,用户可以看到的内容就一定可以爬取,因此无论如何防复制都不是理论安全的,只能说能给想要爬取数据的人增加难度。防复制手段也可以和之后介绍的反调试配合使用,达到更好的效果。
禁用CTRL+C
这个手段和反调试禁用F12是类似的,连业余选手都挡不住,这里就不多介绍了。
使用canvas渲染内容
使用canvas渲染想要防复制的关键内容,也是一种可行的手段。
window.onload = function() {
var canvas = document.querySelector('#canvas');
var ctx = canvas.getContext('2d');
ctx.font = '48px serif';
ctx.fillText('Hello, world!', 50, 50);
};
此外,我们甚至可以将一段文本拆分成多个canvas,或者文本、canvas、服务端返回图片结合使用,来增加非人工读取数据的难度。然而,如果攻击者使用OCR呢?如果他直接截图呢?要知道现在Selenium这类Headless浏览器在爬虫中的应用也是很广泛的。总而言之:防复制代价不小,作用不大。
接口反调试
接口报文奇葩化
前面obfuscator这样一番折腾,相信我们的JavaScript代码已经很难调试了,然而此时前后端通信的报文还是明文的,明文的接口报文其实才是系统中最薄弱的一环,攻击者还是可能从报文中看出系统运行逻辑的一些端倪,甚至完全可以不看源码,仅从报文分析代码和数据处理逻辑,如果要避免这个问题,就要对前后端通信的报文进行某种编码来增加调试难度。
注意:接口反调试一定是基于代码反调试来做的,如果代码没有经过混淆,单独实现接口反调试除了阻碍正常开发以外没有意义。
一种实用的解决方案是将对称密钥的生成逻辑隐晦的埋藏在JavaScript源码中,经过obfuscator混淆后密钥明文是比较难被发现的,然后前后端使用对称加密通信,取代原来的明文JSON数据。
我们这里会用到crypto-js库,执行以下命令安装。
npm install crypto-js
util.js
import CryptoJS from "crypto-js";
export const encrypt = (message, secretKey) => {
const keyData = CryptoJS.enc.Base64.parse(secretKey);
const messageData = CryptoJS.enc.Utf8.parse(message);
return CryptoJS.AES.encrypt(messageData, keyData, {
mode: CryptoJS.mode.ECB,
padding: CryptoJS.pad.Pkcs7,
});
};
export const decrypt = (message, secretKey) => {
const keyData = CryptoJS.enc.Base64.parse(secretKey);
const decryptedData = CryptoJS.AES.decrypt(message, keyData, {
mode: CryptoJS.mode.ECB,
padding: CryptoJS.pad.Pkcs7,
});
return CryptoJS.enc.Utf8.stringify(decryptedData);
};
main.js
import { encrypt, decrypt } from "./util";
window.onload = () => {
let aesKey = "abc";
for (let i = 1; i < 4; i++) {
aesKey += i;
}
const loginButton = document.querySelector("#loginButton");
loginButton.addEventListener("click", () => {
const username = document.querySelector("#username").value;
const password = document.querySelector("#password").value;
const postData = {
username,
password,
};
const encryptedData = encrypt(JSON.stringify(postData), aesKey);
fetch("/login", {
method: "POST",
headers: {
"Content-Type": "text/plain",
},
body: encryptedData,
})
.then((res) => {
return res.text();
})
.then((res) => {
const rspdata = JSON.parse(decrypt(res, aesKey));
console.log(rspdata);
});
});
};
上面代码中我们使用了crypto-js这个库对请求报文进行了AES加密,源数据是一个JSON字符串,它的结果则是一个Base64字符串,我们也可以采用XML、ProtoBuf、甚至自定义的奇怪编码形式进行加密前的编码,密钥虽然是明文写在源码中的,但经过混淆后再想找到密钥也没那么容易,攻击者逆向调试时,难以取得密钥就难以解密报文。
当然,上述实现方式也会给我们正常开发造成困扰,我们开发阶段无法通过浏览器调试工具查看请求响应报文了。分环境使用不同的传输编码实现也有风险,因为开发环境和生产环境不同,就可能存在生产环境特有的bug。这就是为了安全需要付出的额外成本。
隐藏接口URI
上面代码中,我们明确的调用了一个HTTP接口/login,这也能让攻击者获得一些信息,甚至针对性的进行渗透测试,解决该问题的一种方式是将调用的后端路由写在报文中,例如调用接口POST /api实际传递的是如下内容:
{
"route": "/login",
"username": "tom",
"password": "abc123"
}
后端根据route字段的值再具体调用某个函数处理请求。
当然,这种方式对后端代码的实现就很不友好了,路由系统是服务端框架中一个非常重要的功能,也是很多框架并发性能优化的重点,将URI放在请求报文中相当于不再使用后端框架的路由,自己编写这些逻辑功能会相对薄弱,对性能也有较大的负面影响,因此非必要不推荐使用此方案。