Pod容器组
Pod是k8s中最小的可部署单元,Pod可以不是单个的容器而是包含了一组(可能为多个)容器,但这些容器共享网络(因此可以使用localhost来互相通信),也可以挂载同一组共享的数据卷。
Pod的使用
k8s的设计上,Pod是一个短生命周期的组件,例如当应用程序意外宕机,k8s本身可以将Pod删除并在其它节点重建。因此Pod宕机重启、更新、回滚等,都应该由k8s来自动调度,我们是不会手动创建Pod的(尽管可以这样做)。我们一般是通过定义Deployment(部署)的方式,来让k8s自动创建包含应用程序容器的Pod。

图中是我们创建Deployment的yaml配置文件,其中template部分就是Pod的定义。
Pod常用操作
以下命令可以查看所有Pod状态。
kubectl get pods
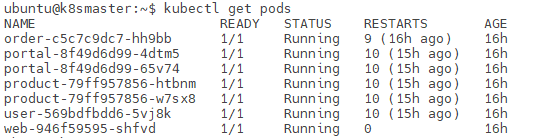
其中STATUS为状态,常见的几种如下表格。
| 状态值 | 说明 |
|---|---|
| Pending | Pod已被k8s接受,但有一个或者多个容器尚未创建且运行,此阶段包括等待Pod被调度的时间和通过网络下载镜像的时间。 |
| Running | Pod已经绑定到了某个节点,Pod中所有的容器都已被创建。至少有一个容器仍在运行,或者正处于启动或重启状态。 |
| Succeeded | Pod中的所有容器都已成功终止,并且不会再重启。 |
| Failed | Pod中的所有容器都已终止,并且至少有一个容器是因为失败终止。也就是说,容器以非0状态退出或者被系统终止。 |
| Unknown | 因为某些原因无法取得Pod的状态。这种情况通常是因为与Pod所在主机通信失败。 |
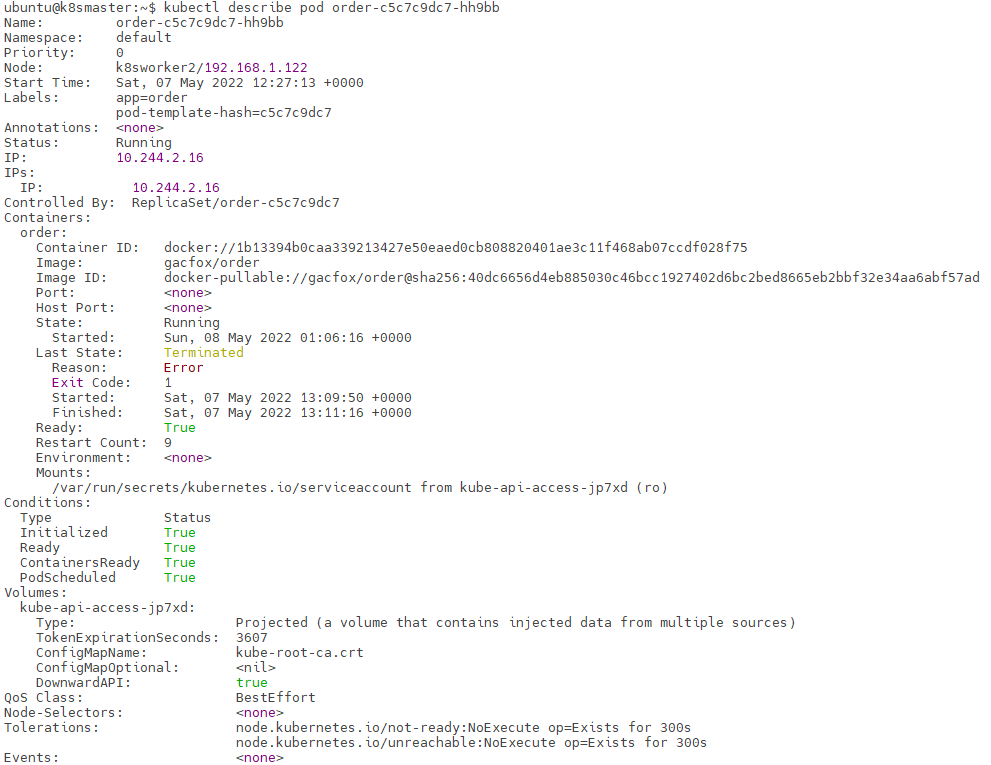
使用如下命令查看Pod详细信息。
kubectl describe pods <Pod名>
使用以下命令查看Pod日志(标准输出的内容).
kubectl logs <Pod名>
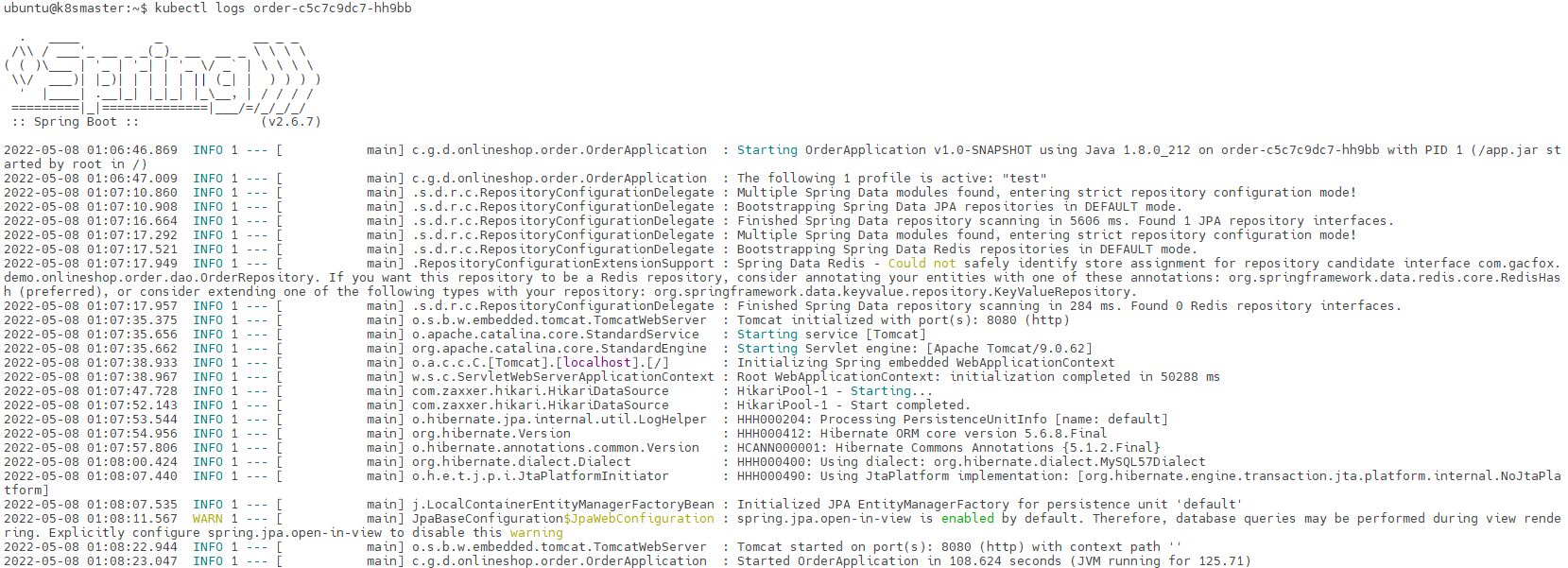
如果我们的程序出现异常情况,我们可以根据以上命令的返回结果来排除故障。
对于一般的应用程序,日志通常不是直接打印在标准输出上的,而是记录在日志文件中,这种情况一般需要进入容器查看,或者去挂载的日志目录查看。
以下命令可以进入Pod执行Bash命令。
kubectl exec -it <Pod名> -- sh

至于Pod的创建、删除、伸缩等操作,一般都是通过操作Deployment来实现,Pod的具体操作由k8s来自动执行。
以下命令可以查看当前Pod的CPU、内存占用情况。
kubectl top pod
Pod常用配置
下面介绍一些有关Pod的常用配置。
镜象拉取策略
imagePullPolicy可以指定容器镜象的拉取策略。
- spec.containers[].imagePullPolicy
例子如下。
containers:
- name: ...
image: ...
imagePullPolicy: Always
Always:默认值,永远从远程仓库拉取IfNotPresent:如果本地不存在该镜象,再从远程仓库拉取Never:不从远程仓库拉取
资源限制
资源限制能够指定容器的上限和下限,k8s调度Pod时会根据这些限制来选择部署的Node(节点)。
- spec.containers[].resources.limits.cpu
- spec.containers[].resources.limits.memory
- spec.containers[].resources.requests.cpu
- spec.containers[].resources.requests.memory
例子如下。
containers:
- name: ...
image: ...
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
- request:指定容器所需的最低资源配置
- limit:指定容器所需的最大资源配置
注:500m可以将其理解为占用0.5个CPU核。
重启机制
重启机制指定容器运行运行结束后,是否重启容器。
- spec.restartPolicy
例子如下。
spec:
containers: ...
restartPolicy: Always
Always:默认值,永远重启容器OnFailure:当容器异常结束(ExitCode不为0)时重启Never:永不重启
健康检查探针
健康检查探针用于检测Pod是否能够正常工作,常用的包括livenessProbe和readinessProbe。前者为存活探针,当探测判定为成功时,容器状态会被设置为RUNNING;当探测判定为失败时,k8s会将容器重启;后者是就绪探针,当探测判定为成功时,Pod可以被网络访问到;当探测判定为失败时,网络中会移除Pod的IP,使得网络流量不会流向该Pod。
健康检查支持三种方式:
ExecAction:在容器内执行特定命令,如果ExitCode为0则认为健康TCPSocketAction:使用TCP连接指定端口,如果握手成功则认位健康HTTPGetAction:对指定端口执行HTTP GET,如果响应码大于等于200且小于400,则认位健康
其中,对于后端服务程序,HTTPGetAction是最常用的。
下面例子中,我们配置了一个存活探针。
containers:
- name: ...
image: ...
livenessProbe:
httpGet:
path: /test
port: 8081
initialDelaySeconds: 60
timeoutSeconds: 5
periodSeconds: 5
successThreshold: 1
failureThreshold: 3
例子中,我们配置了一个HTTP检测的策略,每隔5秒对http://localhost:8081/test发起一个GET请求。存活探针和就绪探针的配置项是类似的:
- initialDelaySeconds:指定容器创建后多久后开始探针的探测,这个参数是因为例如Tomcat等服务可能有一个比较耗时的启动过程,启动完成前健康检查的接口显然也是无法访问的,因此需要一个探测的延迟时间。
- timeoutSeconds:HTTP请求的超时,超过该值判定为探测失败,默认值为1。
- periodSeconds:探测的周期间隔,默认值为10。
- successThreshold:连续探测成功几次后,判定为健康检查成功,默认值为1。
- failureThreshold:连续探测失败几次后,判定为健康检查失败,默认值为3。
我们可以通过kubectl describe pod来查看有关健康检查的详细信息。
节点选择器
有时我们希望特定的应用程序Pod部署到特定类型的Node上,比如IO密集型程序我们希望将其部署在具有SSD的服务器上,但其它Pod没有该要求,这可以通过节点选择器实现。
Node可以配置标签,在部署Pod时可以指定一个标签,使Pod部署到特定Node上。下面命令可以对Node设置标签。
kubectl label node <节点名> <标签键>=<标签值>
例如:kubectl label node k8sworker1 disk-type=ssd
在Pod定义中,我们可以指定该标签。
- spec.nodeSelector
例子如下。
spec:
containers: ...
nodeSelector:
disk-type: ssd
在上面例子中,这样配置后,该Pod就只会被调度到k8sworker1节点上了。