ShardingSphere简介
ShardingSphere是一款关系型数据库的分布式解决方案,该框架能够让我们像操作单个数据库一样操作实现了读写分离和分库分表的多个数据库组成的分布式集群。ShardingSphere起源于国内的当当网,在2018年捐赠给了Apache基金会。
ShardingSphere主要包括ShardingSphere-JDBC和ShardingSphere-Proxy两部分,ShardingSphere-JDBC的定位是一个Java框架,以Jar包的形式分发,在应用层实现了数据库的分布式方案;Sharding-Proxy则是一个透明化的数据库代理中间件,它可以看作一个分布式数据库的服务端并需要独立部署,我们的程序或数据库客户端可以像正常操作单体数据库一样连接Sharding-Proxy。ShardingSphere支持MySQL和PostgreSQL两款数据库。
数据库分布式中间件是个有争议的技术,有些团队采用了此类技术,因为它确实能解决实际问题;但也有一些团队抵制此类框架,认为引入数据库分布式中间件增加了系统复杂度,降低了系统可靠性和可维护性,不如直接研发或采用一款分布式数据库替代MySQL。总而言之,ShardingSphere的出现有其特定的历史背景,个人认为是非必要不使用,但其设计思路值得我们借鉴和学习。
最后要说明一点,ShardingSphere比较难用且坑点极多,而且版本迭代也经常有很多API发生变化,后续文章内容可能在新版本中的配置细节上已经过时,但基本概念是相通的,具体使用时还是要参考官方文档。
官方网站:https://shardingsphere.apache.org/
分布式数据库基本概念
大部分的分布式数据库在实现上都采用了副本集和分片的概念,ShardingSphere也是基于这些概念设计的。副本集表示一份数据存在多个副本,多个副本数据存在于不同的数据库节点上,借此可以实现读写分离架构,将应用的读写操作分散到不同的主机,以减轻写操作对读操作性能的影响;分片则可以将一份巨大的数据通过一定规则划分到不同的数据库和数据表中,通过分库分表来避免数据库的性能瓶颈,提升整体可用性。
读写分离
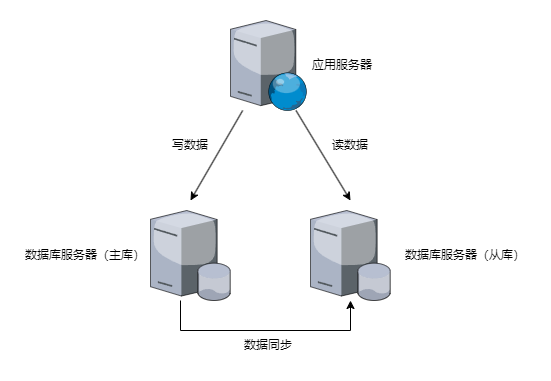
读写分离的实现:
- 根据SQL的语义将操作路由到主库和从库上,主库负责处理事务性的增删改操作,从库负责处理查询操作
- 如果有多个从库,查询操作可以通过一定的负载均衡算法将操作路由到多个从库上,分散计算压力
分库分表
分库分表主要分为垂直划分和水平划分两种方式,实际开发中通常是两者结合使用的。
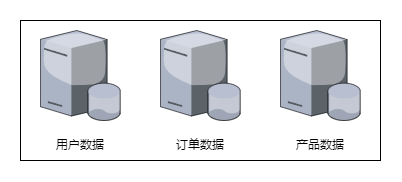
垂直划分比较好理解,例如将原本存储在1个数据库节点的用户信息、订单信息、产品信息分别存储到3个数据库节点中,以减轻单个数据库的压力,这就是一种垂直划分。此外,将一个较宽的大表按列拆分成两个表,以减轻单个表的读写压力,这也是一种垂直划分。
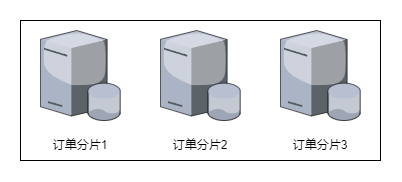
水平划分对应数据分片的概念,相对于垂直划分,水平划分则是根据一定的规则将数据行分到到不同的库或是不同的表中。例如,订单表具有订单号orderNo字段,此时根据orderNo % 3的结果将订单数据分别存储到3个数据库中,这就是一种水平划分。
ShardingSphere的作用
在实际开发中,读写分离和分库分表通常是同时使用的。要想实现在读写分离和分库分表的多个数据库节点上操作数据,有两种方式可以选用:程序代码封装和中间件封装。
程序代码封装:实现一个通用的数据访问层框架,在应用层对程序发出的SQL指令进行路由,以及对多个数据库的查询结果数据进行处理,实现读写分离和分库分表。ShardingSphere-JDBC就是一个这样的框架。
中间件封装:实现一个数据库代理中间件,应用程序通过标准的数据库访问协议和中间件通信,发送标准的SQL指令,由中间件负责对指令进行路由和数据进行处理,并将结果返回给应用服务器。在应用服务器看来,操作的是单个数据库。ShardingSphere-Proxy就是一个这样的分布式中间件。
补充:MySQL主从同步库搭建
这里我们简单介绍下如何搭建MySQL的主从同步实验环境。MySQL支持主从同步模式,从库能够基于主库的binlog对数据进行复制,一个主库可以对应多个从库,我们这里简单起见就搭建1主1从两个数据库节点。由于安装多个MySQL比较麻烦,因此建议使用Docker搭建实验环境,Windows下可以使用DockerDesktop软件,Linux下直接安装Docker即可,具体可以参考Docker相关章节。
主库挂载的数据库配置文件my.cnf:
[mysqld]
# 服务器ID
server-id=1
# binlog设置日志格式
binlog_format=ROW
# 记录binlog的数据库
binlog-do-db=netstore
# binlog日志名
log-bin=binlog
从库挂载的数据库配置文件my.cnf:
[mysqld]
# 服务器ID
server-id=2

注意:如果使用Windows的DockerDesktop搭建实验环境,需要将Windows下挂载的配置文件属性修改为只读,Linux下则需要将文件权限修改为0444,否则MySQL将拒绝读取该配置文件,报错为World-writable config file '/etc/mysql/conf.d/my.cnf' is ignored.,这应当是MySQL在配置文件权限处理上和Docker的理念不一致造成的问题,不知道后续版本是否会改进。
使用Docker启动主库和从库容器:
docker run --name master -v /d/conf/master:/etc/mysql/conf.d -e MYSQL_ROOT_PASSWORD=root -p 3306:3306 -d mysql:5.7
docker run --name slave -v /d/conf/slave:/etc/mysql/conf.d -e MYSQL_ROOT_PASSWORD=root -p 3307:3306 -d mysql:5.7
主从数据库启动后,我们还需要在主库中创建slave用户并赋予权限。我们在主库中执行以下命令:
-- 创建slave用户
CREATE USER 'slave'@'%' IDENTIFIED BY '123456';
-- 授予复制权限
GRANT REPLICATION SLAVE ON *.* TO 'slave'@'%';
-- 刷新权限
FLUSH PRIVILEGES;
在主数据库中,我们执行以下命令查看binlog状态:
SHOW MASTER STATUS;
输出例子如下:

在从库中,我们执行以下命令配置主从关系:
CHANGE MASTER TO MASTER_HOST = '192.168.1.3',
MASTER_USER = 'slave',
MASTER_PASSWORD = '123456',
MASTER_PORT = 3306,
MASTER_LOG_FILE = 'binlog.000001',
MASTER_LOG_POS = 154;
配置后,在从库启动同步:
START SLAVE;
在从库执行以下命令查看同步状态:
SHOW SLAVE STATUS;
如果输出Slave_IO_Running和Slave_SQL_Running都为Yes,说明我们搭建的主从同步已经成功。此时可以在主库中插入数据查看效果了。