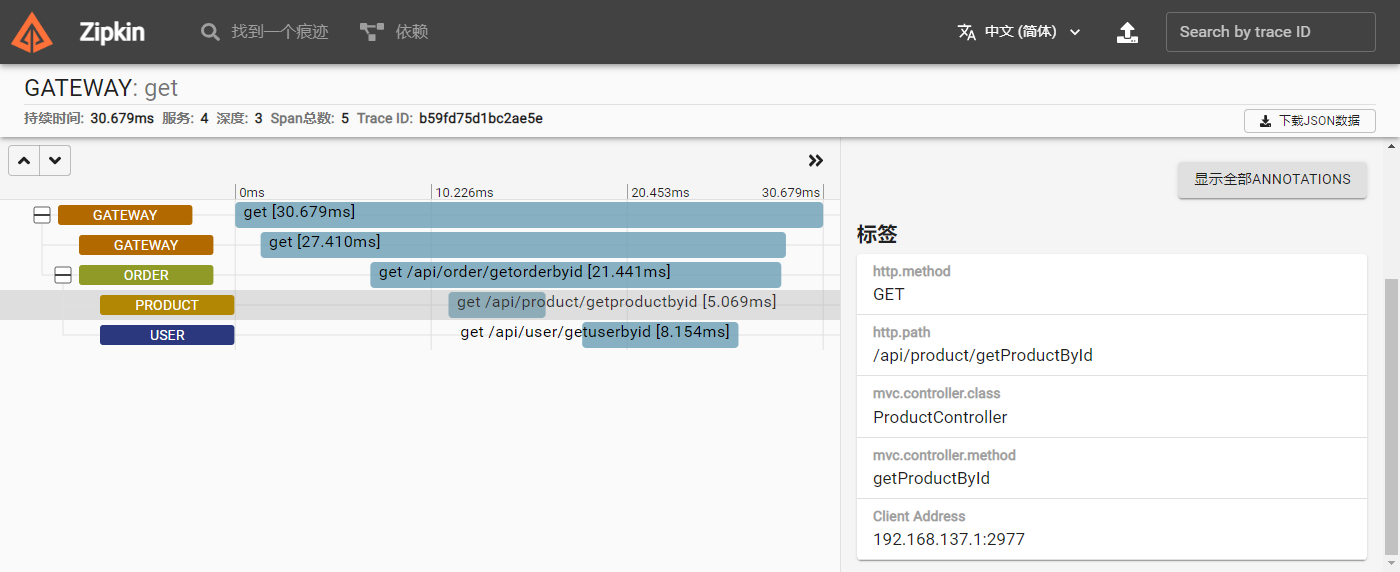
Sleuth链路跟踪
SpringCloud Sleuth用于整合调用链日志服务,它的使用非常方便,只需简单添加几行配置就能使用,这里以集成Zipkin为例进行介绍。
引入Maven依赖
在pom.xml中,我们需要引入SpringCloud Sleuth以及Zipkin依赖。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
使用Docker安装Zipkin服务
简单起见,我们这里直接使用Docker镜像方式运行Zipkin服务。
docker run --name zipkin -d -p 9411:9411 openzipkin/zipkin
Zipkin运行起来后,我们可以使用浏览器访问9411端口查看页面。
工程配置
application.properties
spring.sleuth.sampler.probability=100
spring.zipkin.baseUrl= http://localhost:9411
配置中,probability是采样率,如果我们的服务调用日志非常庞大超出了网络和Zipkin服务的负载能力,可以适当降低采样率;baseUrl配置了Zipkin服务的地址。
这样配置以后,正常启动工程其实调用链日志系统就可以正常工作了。
作者:Gacfox
版权声明:本网站为非盈利性质,文章如非特殊说明均为原创,版权遵循知识共享协议CC BY-NC-ND 4.0进行授权,转载必须署名,禁止用于商业目的或演绎修改后转载。