SpringWebFlux简介
我们知道对于Web服务来说,并发模型主要有传统的多线程模型和后来逐渐流行起来的异步模型。基于传统ServletAPI的框架(如SpringMVC)都属于前者,Tomcat等Servlet容器提供了基于线程池的多线程并发模型,具体业务代码全部采用同步阻塞的方式开发,其优点是使用简单、开发调试方便,这种模型适合比较复杂的业务逻辑编写;而新兴的Node.js等属于后者,异步并发模型天生适合IO密集型的高并发服务端程序编写,当然这种模型的缺点是代码扭曲,难写、难调试,但异步模型却非常适合用来实现高性能网关、接口的聚合层这类组件。
JavaEE中,在Servlet3.0规范里也引入了异步Servlet支持,而Spring5引入了一套异步非阻塞模型的Web服务框架SpringWebFlux。SpringWebFlux基于ReactorCore响应式编程框架实现,能够基于Netty运行也能够基于异步Servlet容器运行。SpringCloud生态中的SpringCloudGateWay微服务网关就是基于SpringWebFlux实现的。
此外,不只是SpringWebFlux,Spring实际上提供了整套的Reactive响应式编程框架,包括基于异步模型的HTTP客户端WebClient,异步的数据访问框架SpringDataMongoDBReactive、SpringDataRedisReactive等。如果我们的一个工程打算采用SpringWebFlux,那么就需要全套的Reactive方案。
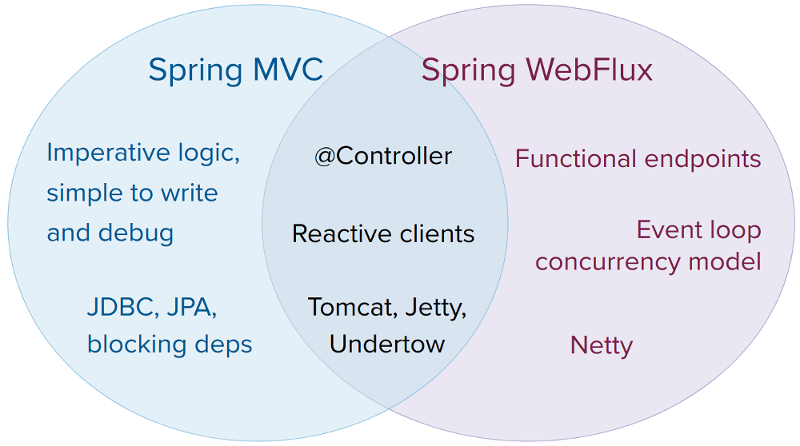
SpringWebFlux和SpringMVC对比
SpringWebFlux并不是一个可以替代SpringMVC的方案,它是一个有着明确适用场景的框架。SpringWebFlux的优点是能够实现高并发服务,在同样的硬件条件和副本数下能够提供比SpringMVC更高的连接数,此外结合采用了异步并发模型的HTTP客户端、数据库访问等框架,能够使我们的服务整体上就是一个高并发的架构。然而,SpringWebFlux的缺点也不能忽视:
- 使用SpringWebFlux就必须整个工程都使用异步编程模型来开发,传统的同步式IO、HTTP客户端、JDBC、以及一些其它同步阻塞模式的API都不可以使用,否则就失去了基于SpringWebFlux框架开发的意义。
- 响应式编程写出的代码是“扭曲”的,它不同于传统的同步阻塞式代码,对一些新手来说理解并掌握响应式编程不是一件容易的事情,尤其是要编写一些复杂业务逻辑的时候,它具有很高的使用门槛。
- 不同于同步阻塞式代码所有操作都在一个线程里,异步并发模型编写的代码难以调试。
- Java生态中有大量依赖于同步阻塞式模型的组件,比如很多日志框架中都有的基于
ThreadLocal的MDC,如果放到异步模型下这些组件就无法直接使用了。
引入SpringWebFlux依赖
这里我们以SpringBoot环境为标准进行介绍。要想使用SpringWebFlux,我们需要引入其起步依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
注意spring-boot-starter-webflux和spring-boot-starter-web是不可以共存的,这决定了我们整个工程的编程模型,只能二选一。
SpringWebFlux简单例子
这里我们以SpringWebFlux和MongoDB数据库为例,编写一个简单的数据插入和查询例子。
User.java
package com.gacfox.demo.model;
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.mongodb.core.mapping.Document;
@Data
@Document(collection = "user")
public class User {
@Id
private String userId;
private String username;
private int age;
}
上面代码定义了一个实体类,这里我们使用了一些MongoDB需要的注解对类进行了标注,指定了其集合名和主键字段。
DemoController.java
package com.gacfox.demo.controller;
import com.gacfox.demo.model.User;
import com.gacfox.demo.repository.UserRepository;
import org.springframework.web.bind.annotation.*;
import reactor.core.publisher.Mono;
import javax.annotation.Resource;
@RestController
@RequestMapping("/demo")
public class DemoController {
@Resource
private UserRepository userRepository;
@GetMapping("/getUserById")
public Mono<User> getUserById(String userId) {
return userRepository.findById(userId);
}
@PostMapping("/addUser")
public Mono<User> addUser(@RequestBody User user) {
user.setUserId(null);
return userRepository.save(user);
}
}
上面代码是SpringWebFlux的控制器,我们发现其写法和SpringMVC十分类似,其实这是Spring为了方便我们理解,特意将SpringWebFlux的控制器封装的和SpringMVC一样,唯一的区别是我们的控制器方法返回的是Mono对象,这是ReactorCore框架提供的响应式对象。对于ReactorCore的使用我们将在下一章节中介绍。除了这种Controller写法,SpringWebFlux还提供了更扭曲的RouterFunction写法,我们将在后文介绍。
UserRepository.java
package com.gacfox.demo.repository;
import com.gacfox.demo.model.User;
import org.springframework.data.mongodb.repository.ReactiveMongoRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface UserRepository extends ReactiveMongoRepository<User, String> {
}
这里持久层接口我们继承了ReactiveMongoRepository,其中默认实现了一些CRUD方法供我们使用。这里注意我们使用的数据库访问框架是spring-boot-starter-data-mongodb-reactive,它是一个支持Reactive的MongoDB数据库操作框架,用法上很类似我们熟悉的SpringDataJPA,区别则是其返回的都是ReactorCore封装好的响应式对象。
运行工程后,我们可以调用/demo/addUser添加用户,调用/demo/getUserById查询用户。