中间件
前面章节我们学习了LangChain中如何使用create_agent()创建智能体,在LangChain 1.x中,智能体其实还有一个非常重要的概念,中间件(Middleware),它其实实现了AOP编程,是智能体与模型调用之间的可插拔拦截层,使用中间件能让我们精确控制智能体执行循环中的每一个关键环节,而无需修改核心逻辑。这篇笔记我们介绍LangChain内置中间件的使用、如何配置参数,以及如何通过装饰器和类实现自定义中间件。
智能体中间件的使用场景
智能体中,中间件主要适用于以下场景:
- 上下文管理:对话历史压缩、动态调整系统提示词
- 安全与合规:隐私信息检测与脱敏、内容审核、工具调用人工审批
- 可靠性保障:模型调用重试、工具调用重试、实现备用模型Fallback
- 监控与调试:日志记录、性能追踪、调用次数统计
中间件执行顺序和钩子(Hook)
LangChain中我们能够创建一个reAct风格的智能体,在智能体的执行循环中,中间件提供了如下几个钩子插入点。
flowchart TD
A([用户输入]) --> B[before_agent]
B --> C[before_model]
C --> D[modify_model_request]
D --> E[LLM 调用]
E --> F[after_model]
F --> G{需要调用工具?}
G -- 是 --> H[wrap_tool_call]
H --> I[执行工具]
I --> C
G -- 否 --> J[after_agent]
J --> K([输出])
style A fill:#4a9eff,color:#fff,stroke:none
style K fill:#4a9eff,color:#fff,stroke:none
style E fill:#f59e0b,color:#fff,stroke:none
style I fill:#f59e0b,color:#fff,stroke:none
钩子的作用如下:
- before_agent:智能体调用开始前触发一次,可用于设置初始化状态或做输入检查
- before_model:每次调用LLM前触发,可用于拦截调用、裁剪消息等
- modify_model_request:在
before_model之后、LLM调用之前,专门用于修改本次请求内容,如动态切换模型、调整工具列表、修改系统提示词等 - after_model:LLM返回后立即触发,可验证输出、脱敏、或根据结果跳转
- wrap_model_call:包裹整个模型调用,适合实现重试、缓存、Fallback等逻辑
- wrap_tool_call:包裹每次工具调用,适合工具调用重试、日志记录
- after_agent:智能体调用结束后触发,适合做输出级别的后处理
使用内置中间件
LangChain 1.x内置了多个开箱即用的中间件,使用create_agent()创建智能体时,可通过middleware参数传入中间件列表,这里我们对这些内置中间件简单介绍一下。
使用内置中间件例子
内置中间件SummarizationMiddleware用于解决长对话超出模型上下文窗口的问题,它会在每次调用模型前(基于before_model钩子)检查当前消息历史的token数量或消息条数,达到触发阈值时自动调用模型对历史对话进行摘要,同时保留最近的若干条消息,实现裁剪上下文的目的但又不让LLM完全“失忆”的目的。这里我们就以SummarizationMiddleware为例演示内置中间件的用法。
为了触发SummarizationMiddleware,下面代码中使用了InMemorySaver来实现多轮对话智能体,有关多轮对话智能体我们将在后续章节详细介绍,这里不是重点。执行代码后,我们可以通过多次与智能体交互触发4000个tokens的条件,执行SummarizationMiddleware中的逻辑。
from langchain.agents.middleware import SummarizationMiddleware
from langchain_openai import ChatOpenAI
from langgraph.checkpoint.memory import InMemorySaver
from langchain.agents import create_agent
model = ChatOpenAI(
model="qwen3:30b-a3b",
base_url="http://localhost:11434/v1/",
api_key="dummy",
temperature=1,
top_p=1,
max_tokens=16384,
timeout=120,
max_retries=6
)
agent = create_agent(
model=model,
system_prompt="You are a helpful AI assistant",
checkpointer=InMemorySaver(),
middleware=[
SummarizationMiddleware(
model=model,
trigger=("tokens", 4000),
keep=("messages", 5),
),
],
)
config = {"configurable": {"thread_id": "1"}}
while True:
user_input = input()
if user_input == "/exit":
break
result = agent.invoke(
{"messages": [{"role": "user", "content": user_input}]},
config=config,
)
print(result['messages'][-1].content)
执行代码后,我们可以通过LangSmith观察SummarizationMiddleware是否被触发了,如果一切正常,我们会在tokens超过限制后观察到如下结果。
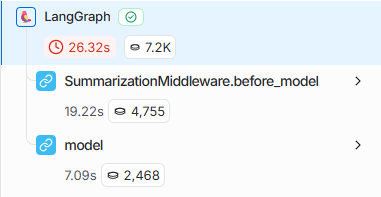
trigger参数支持多种触发条件写法,包括tokens数触发、消息数触发、组合多个条件等。
# 单条件:tokens数>= 4000时触发
trigger=("tokens", 4000)
# 单条件:消息条数>=10时触发
trigger=("messages", 10)
# 多条件(任一满足则触发)
trigger=[("tokens", 3000), ("messages", 6)]
keep参数的写法与trigger类似,它用于指定摘要时需要保留的最近内容量。
其他内置中间件
基于LangChain官方文档,目前有以下内置中间件可用。
| 中间件英文名称 | 中文名称 | 主要功能描述 |
|---|---|---|
| Summarization | 对话总结 | 接近tokens限制时自动总结历史对话 |
| Human-in-the-loop | 人工介入 / 人机协同 | 在执行工具调用前暂停等待人工审批、编辑或拒绝 |
| Model call limit | 模型调用次数限制 | 限制总的模型调用次数,防止成本失控或死循环 |
| Tool call limit | 工具调用次数限制 | 限制工具调用次数(可全局或针对特定工具) |
| Model fallback | 模型自动降级 / 后备模型 | 主模型失败时自动切换到备选模型 |
| PII detection | 个人信息(PII)检测与处理 | 检测并处理对话中的敏感个人信息(邮箱、信用卡等) |
| To-do list | 待办事项列表 | 为代理提供任务规划与跟踪能力 |
| LLM tool selector | LLM工具选择器 | 先用小模型筛选相关工具,减少主模型tokens消耗 |
| Tool retry | 工具调用自动重试 | 工具调用失败时自动重试(指数退避) |
| Model retry | 模型调用自动重试 | 模型调用失败时自动重试(指数退避) |
| LLM tool emulator | LLM工具模拟器 | 用LLM模拟工具执行结果(主要用于测试) |
| Context editing | 上下文编辑 | 清理旧的工具调用输出,控制上下文长度 |
| Shell tool | Shell工具 | 提供持久化的Shell会话给代理执行命令 |
| File search | 文件搜索 | 提供glob和grep工具,用于文件系统搜索 |
| Filesystem | 文件系统工具(Deep Agents) | 提供ls/read/write/edit文件工具,支持长期记忆 |
| Subagent | 子代理 | 支持创建并委派任务给子代理,隔离上下文 |
自定义中间件
当内置中间件无法满足需求时,我们也可以自己实现。LangChain 1.x中,自定义中间件有两种方式:装饰器和类。前者适合单钩子的简单场景,后者适合适合多钩子组合或需要维护状态的场景。
装饰器中间件
装饰器中间件比较简洁,它需要用@before_model、@after_model、@wrap_model_call等装饰器标注一个普通函数,然后将其作为中间件传入create_agent()。
from langchain.agents import create_agent
from langchain.agents.middleware import (
before_model,
after_model,
wrap_model_call,
AgentState,
ModelRequest,
ModelResponse,
)
from langchain_openai import ChatOpenAI
from langgraph.runtime import Runtime
from typing import Any, Callable
model = ChatOpenAI(
model="qwen3:30b-a3b",
base_url="http://localhost:11434/v1/",
api_key="dummy",
temperature=1,
top_p=1,
max_tokens=16384,
timeout=120,
max_retries=6
)
@before_model
def log_before_model(state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
"""每次调用 LLM 前打印消息数量。"""
print(f"[中间件] 即将调用模型,当前消息数:{len(state['messages'])}")
return None # 返回 None 表示不修改状态,继续正常流程
@after_model
def log_after_model(state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
"""每次 LLM 返回后打印最新输出。"""
last_msg = state["messages"][-1]
print(f"[中间件] 模型返回:{last_msg.content[:100]}...")
return None
@wrap_model_call
def retry_model_call(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ModelResponse:
"""为模型调用添加简单重试逻辑。"""
for attempt in range(3):
try:
return handler(request)
except Exception as e:
if attempt == 2:
raise
print(f"[中间件] 第 {attempt + 1} 次重试,错误:{e}")
agent = create_agent(
model=model,
tools=[],
middleware=[log_before_model, log_after_model, retry_model_call],
)
agent.invoke({"messages": [{"role": "user", "content": "你好"}]})
before_model和after_model钩子函数接收state和runtime两个参数,state参数中包含了当前状态,返回值是一个用于更新状态的字典,或返回None表示不做任何修改。wrap_model_call钩子中,request封装了本次模型请求,handler代表后续所有中间件与实际模型调用的回调,由我们决定是否调用handler,以及调用几次。
类中间件
除了使用装饰器包装函数实现中间件,我们也可以继承AgentMiddleware类实现类中间件。相比最简单的装饰器中间件,类中间件内部可以维护一些成员变量状态。下面例子实现了一个统计每次模型调用耗时的中间件。
import time
from typing import Callable
from langchain.agents import create_agent
from langchain.agents.middleware import (
ModelRequest,
ModelResponse, AgentMiddleware,
)
from langchain_openai import ChatOpenAI
model = ChatOpenAI(
model="qwen3:30b-a3b",
base_url="http://localhost:11434/v1/",
api_key="dummy",
temperature=1,
top_p=1,
max_tokens=16384,
timeout=120,
max_retries=6
)
class TimingMiddleware(AgentMiddleware):
"""统计每次模型调用耗时的中间件"""
def __init__(self):
super().__init__()
self._call_times: list[float] = []
def wrap_model_call(
self,
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ModelResponse:
start = time.time()
response = handler(request)
elapsed = time.time() - start
self._call_times.append(elapsed)
print(f"[TimingMiddleware] 本次调用耗时 {elapsed:.2f}s,"
f"平均耗时 {sum(self._call_times) / len(self._call_times):.2f}s")
return response
agent = create_agent(
model=model,
tools=[],
middleware=[TimingMiddleware()],
)
agent.invoke({"messages": [{"role": "user", "content": "你好"}]})
自定义状态扩展
有时中间件需要在智能体状态AgentState中存储自己的数据,这可以通过state_schema属性来扩展。AgentState派生自TypedDict,因此我们对AgentState的扩展也必须是TypedDict类型。
from langchain.agents.middleware import AgentMiddleware, AgentState
from langchain_core.messages import HumanMessage
from langchain.agents import create_agent
from langchain_openai import ChatOpenAI
from typing_extensions import NotRequired
from typing import Any
model = ChatOpenAI(
model="qwen3:30b-a3b",
base_url="http://localhost:11434/v1/",
api_key="dummy",
temperature=1,
top_p=1,
max_tokens=16384,
timeout=120,
max_retries=6
)
class CounterState(AgentState):
"""扩展AgentState,增加调用计数字段"""
model_call_count: NotRequired[int]
class CallCounterMiddleware(AgentMiddleware[CounterState]):
"""统计模型调用次数,超过10次后终止"""
state_schema = CounterState
def before_model(self, state: CounterState, runtime) -> dict[str, Any] | None:
count = state.get("model_call_count", 0)
if count >= 10:
return {"jump_to": "end"}
return None
def after_model(self, state: CounterState, runtime) -> dict[str, Any] | None:
return {"model_call_count": state.get("model_call_count", 0) + 1}
agent = create_agent(
model=model,
middleware=[CallCounterMiddleware()],
tools=[],
)
# 调用时需要提供初始状态
result = agent.invoke({
"messages": [HumanMessage("你好")],
"model_call_count": 0,
})
dynamic_prompt动态系统提示词
除了上述钩子之外,LangChain 1.x还提供了@dynamic_prompt装饰器,专门用于根据运行时状态动态设置系统提示词,这在需要根据用户身份、当前任务阶段等上下文动态调整Agent行为时非常有用。
from langchain.agents import create_agent
from langchain.agents.middleware import dynamic_prompt, ModelRequest
from langchain_core.messages import HumanMessage
from langchain_openai import ChatOpenAI
model = ChatOpenAI(
model="qwen3:30b-a3b",
base_url="http://localhost:11434/v1/",
api_key="dummy",
temperature=1,
top_p=1,
max_tokens=16384,
timeout=120,
max_retries=6
)
@dynamic_prompt
def role_based_prompt(request: ModelRequest) -> str | None:
"""根据消息内容动态调整系统提示词"""
messages = request.state.get("messages", [])
if messages and "代码" in messages[-1].content:
return "You are an expert software engineer. Prioritize clean, well-documented code."
return "You are a helpful AI assistant."
agent = create_agent(
model=model,
tools=[],
middleware=[role_based_prompt],
)
# 调用时需要提供初始状态
result = agent.invoke({
"messages": [HumanMessage("你好")],
"model_call_count": 0,
})