SQLAlchemy简介

SQLAlchemy是一款Python中流行的数据库ORM框架,相比直接使用PyMySQL或mysqliteclient库,SQLAlchemy能够屏蔽底层的SQL语言,而且框架还提供了数据模型、关联映射等高级特性,能够简化数据操作逻辑的编写。SQLAlchemy当前的最新版本是2.0,这个版本相比过去的1.x在API上有一定变化,这篇笔记我们将对SQLAlchemy2.0版本的使用进行介绍。
官方网站:https://www.sqlalchemy.org/
SQLAlchemy框架概述
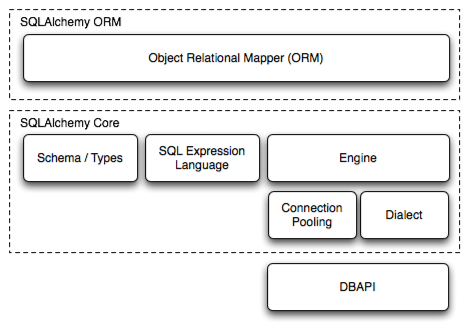
SQLAlchemy框架主要分为两部分,Core和ORM。
SQLAlchemy Core:Core部分提供的Engine对象是SQLAlchemy与数据库之间的接口,它负责执行SQL语句、连接管理、事务控制等。此外Core部分还实现了对数据库通用底层操作的封装,使开发者能够直接构建SQL语句,控制底层数据库操作。
SQLAlchemy ORM:ORM部分提供了对象关系映射功能,是基于Core实现的更高级抽象封装。ORM使用Session的概念管理持久化对象的生命周期,开发者通常通过定义模型类来映射数据库表,并通过Session进行CRUD操作,大部分ORM框架都有类似的设计。
SQLAlchemy框架的这种设计能让我们既能用上全功能ORM的便利性也不失底层操作的灵活性。实际开发中,这两部分通常是结合使用的。
在项目中安装SQLAlchemy
执行以下pip命令安装SQLAlchemy框架(建议创建venv虚拟环境安装)。
pip install SQLAlchemy
SQLAlchemy支持多种关系型数据库系统,我们后续章节都将基于MySQL数据库进行介绍。不过SQLAlchemy使用MySQL还需要安装相关的客户端库,MySQL在Python中主要有PyMySQL和mysqliteclient两个客户端库,我们这里选择PyMySQL。
pip install PyMySQL
注意:
- 关于PyMySQL和mysqliteclient,两个都是MySQL数据库的客户端库。PyMySQL比较新,它是纯Python编写的,兼容性较好,适合轻量级应用;而mysqliteclient使用了C扩展的底层实现,理论上更为成熟且在性能上更强,但它安装比较复杂,在某些操作系统下可能还需要安装C编译器,我们这里出于简单起见选择了PyMySQL作为演示的例子,实际开发中我们需要根据实际情况选择。
- PyMySQL和mysqliteclient都是同步阻塞式的MySQL客户端库,如果我们需要用异步非阻塞客户端库,需要考虑aiomysql库。有关SQLAlchemy对异步操作的支持将在后续章节介绍。
使用SQLAlchemy
我们这里写一个最简单的例子,使用SQLAlchemy ORM定义数据模型并查询数据。为了项目结构清晰,我们创建如下两个Python源代码文件。
demo-alchemy
|_ models.py # 数据模型类定义
|_ main.py # 主程序文件
我们操作的数据表t_customer如下。
CREATE TABLE `t_customer` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`phone` varchar(45) NOT NULL,
PRIMARY KEY (`id`)
)
models.py
from sqlalchemy import BigInteger, String
from sqlalchemy.orm import mapped_column, DeclarativeBase, Mapped
class Base(DeclarativeBase):
pass
class Customer(Base):
__tablename__ = 't_customer'
id: Mapped[int] = mapped_column(BigInteger, primary_key=True)
name: Mapped[str] = mapped_column(String(255), nullable=False)
phone: Mapped[str] = mapped_column(String(45), nullable=False)
def __repr__(self):
return f"Customer(id={self.id}, name='{self.name}', phone='{self.phone}')"
models.py中我们定义了一个Customer类,它和我们的数据表完全对应。数据模型类都需要继承SQLAlchemy提供的基类DeclarativeBase,不过出于元数据统一管理和代码可复用性考虑,我们通常还需要定义一个自己的基类Base,这也是SQLAlchemy官方推荐的用法。
Customer类中,__tablename__指定了映射的数据表名,id、name、phone都是数据表中同名的字段,这些列对象使用mapped_column()函数创建,它们共同定义了类中的各个字段如何映射到数据库表上,此外它们其实还用了可选的Mapped[]类型标注,这些类型标注主要用于用于类型检查器和IDE的智能提示,它们本身并不影响ORM框架的具体行为。最后我们还提供了一个魔术方法__repr__(),它用于在调试阶段在控制台上打印数据模型时,能够输出恰当的字符串信息。
注意:为什么这里都使用类属性来定义字段,而非实例属性呢?数据模型类是SQLAlchemy中的一种特殊类,我们不能以正常的Python类来理解,这些映射字段使用类属性是因为SQLAlchemy需要这些类属性来通过反射进行关联映射,SQLAlchemy查询到的具体数据封装为对象时还会在额外设置实例属性,因此并不是说这里字段定义为了类属性它的实例就不能修改数据了,我们操作SQLAlchemy查询到的实例时,操作的仍是实例属性。
main.py
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from models import Customer
if __name__ == '__main__':
DATABASE_URL = 'mysql+pymysql://root:root@localhost:3306/netstore'
engine = create_engine(DATABASE_URL, echo=True, future=True)
SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
with SessionLocal() as db:
for customer in db.query(Customer).all():
print(customer)
main.py中的代码就比较好理解了,我们先创建了Engine对象,它是我们和数据库交互的基础,echo参数表示是否在控制台或日志上打印生成SQL语句,在开发阶段我们可以将其打开;future参数用来开启SQLAlchemy 2.0版本的行为,我们保持开启即可。除此之外,SQLAlchemy默认使用了连接池,在create_engine()函数中我们还可以配置连接池相关的几个参数,包括连接池中保持常驻的连接数pool_size、允许额外创建的连接数max_overflow、请求连接时等待的最大秒数pool_timeout、是否主动回收连接pool_recycle等。
随后我们调用sessionmaker()函数创建了一个Session对象,我们的ORM操作都需要基于这个Session对象实现。最后我们调用了query(数据模型类).all()方法查询了一个表中的所有数据并打印了出来。
关于代码中使用的连接串,mysql是使用的数据库类型,pymysql是使用的客户端库,root:root是我们MySQL数据库的用户名和密码,localhost:3306是数据库服务器的主机名和地址,netstore是数据库Schema名。SQLAlchemy连接其它数据库时也需要遵循类似的格式拼接连接串,实际开发中,我们通常需要将这个连接串放在单独的配置文件中。